This content has been archived. It may no longer be relevant
“Beware the Jabberwock, my son!
The jaws that bite, the claws that catch!
Beware the Jubjub bird, and shun
The frumious Bandersnatch!”
— Lewis Carroll
Verbatim coding seems a natural application for machine learning. After all, for important large projects and trackers we often have lots of properly coded verbatims. These seem perfect for machine learning. Just tell the computer to learn from these examples, and voilà! We have a machine learning model that can code new responses and mimic the human coding. Sadly, it is not that simple.
Machine Learning Basics
To understand why, you need to know just a bit about how machine learning works. When we give the computer a bunch of coded verbatims and ask it to learn how to code them we are doing supervised machine learning. In other words, we are not just asking the computer to “figure it out”. We are showing it how proper coding is done for our codeframe and telling it to learn how to code similarly. The result of the machine learning process is a model containing the rules based on what the computer has learned. Using the model, the computer can try to code new verbatims in a manner that mimics the examples from which it has learned.
There are many supervised machine learning tools with different topics, information, algorithms, and features out there. Amazon Web Services offers several, which you can read about here if you have interest. There are even machine learning engines developed specifically for coding survey responses. One of these was offered by Ascribe for several years. The problem with these tools is that the machine learning model is opaque. You can’t look inside the model to understand why it makes its decisions.
Problems with Opaque Machine Learning Models
So why are opaque models bad? Let’s suppose you train up a nice machine learning model for a tracker study you have fielded for several waves. In comes the next wave, and you code it automatically with the model. It won’t get it perfect of course. You will have some verbatims where a code was applied when it should not have been. This is a False Positive, or an error of commission. You will also find verbatims where a code was not applied that should have been. This is a False Negative, or error of omission. How do we now correct the model so that it does not make these mistakes again?
Correcting False Negatives
Correcting false negatives is not too difficult, at least in theory. You just come up with more examples of where the code is correctly applied to a verbatim. You put these new examples in the training set, build the model again, and hopefully the number of these false negatives decreases. Hopefully. If not, you lather, rinse, and repeat.
Correcting False Positives
Correcting false positives can get maddening. For this you need more examples where the code was correctly not applied to a verbatim. But what examples? And how many? In practice the number of examples to correct false positives can be far larger than to correct false negatives.
The Frumious Downward Accuracy Spiral
One of the promises of machine learning is that over time you have more and more training examples, so you can retrain the model with these new examples and the model will continue to improve, right? Wrong. If you retrain with new examples provided by using your machine learning model the accuracy will go down, not up. Text mining and natural language processing are related technologies that help companies understand more about text analytics that they work with on a daily basis. Using examples containing mistakes from the natural language machine learning model reinforces those mistakes. You can avoid this by thoroughly checking the different verbatims coded within the machine learning tool and using these corrected examples to retrain the model. But who is going to do that? This error checking takes a good fraction of the time that would be required to simply manually code the verbatims. The whole point of using natural language machine learning is not to spend this time and to make the best use of your time through the help and use of NLP. So, either the model gets worse over time, or you spend nearly as much labor and work on your training set as if you were not using the machine learning tool.
Learn more about how text mining can impact businesses.
Explainable Machine Learning Models
It would be great if you could ask the machine learning model why it made the decision that led to a coding error. If you knew that, at least you would be in a better position to conjure up new training examples within machine learning text analysis to try to fix the problems. It would be even better if you could simply correct that decision logic in the model without needing to retrain the model or find new training examples.
This has led different companies like IBM to research Explainable AI tools. The IBM AI Explainability 360 project is an example of this work, but other researchers are also pursuing this concept.
At Ascribe we are developing a machine learning tool that is both explainable and correctable. In other words, you can look inside the machine learning model to best understand why it makes its decisions, and you can correct these decisions as well if needed.
Structure of an Explainable Machine Learning Model for Verbatim Coding
For verbatim coding, we need a machine learning model that contains a set of rules for each code within the codeframe. For a given verbatim, if a rule for a code matches the verbatim, then the code is applied to the verbatim. If the rules are written in a way that humans can understand, then we have a machine learning model that can be understood and if necessary corrected.
The approach we have taken at Ascribe is to create rules using regular expressions. To be precise, we use an extension of regular expressions as explained in this post. A simplistic way to approach this would be to simply create a set of rules that attempt to match the verbatim directly. This can be a reasonable approach, particularly for short format verbatim responses. We can do better than that, however. A far more powerful approach to support this sentiment analysis is to first run the verbatims through natural language processing (NLP). This results in findings consisting of topics, expressions, extracts, and sentiment scores. Each verbatim comment can produce many findings, containing these NLP elements, which we call the facets of the finding. Natural language processing works well across the board for processing sentiment analysis and understanding the text analysis results to build algorithms and different features.
You can read more about NLP in this blog post, but for our purposes we can define the facets of a finding as:
- Verbatim: the original comment itself.
- Topic: what the person is talking about. Typically a noun or noun phrase.
- Expression: what the person is saying about the topic. Often a verb or adverbial phrase.
- Extract: the portion of the verbatim that yielded the topic and expression, with extraneous sections such as punctuation removed.
- Sentiment score: positive or negative if sentiment is expressed, or empty if there is no expression of sentiment.
Rules in the Machine Learning Model
Armed with the NLP findings for a verbatim we can build regular expression rules to match the facets of each NLP finding to build accurate results. A rule has a regular expression for each facet in the text analysis. If the regular expression for a facet is empty it always matches that facet. Each rule must have a regular expression for at least one facet in the text analysis. If there are multiple regular expressions for the facets of a rule, they must all match the NLP finding to produce a positive match in the algorithm.
Let’s look at a specific example. Suppose we have a code in our codeframe:
- Liked advertisement / product description
Two appropriate rules using the Topic and Expression of the NLP findings would be:

The first rule matches a verbatim where the respondent likes the product description, and the second a verbatim where the respondent likes the ad or advertisement. The | character in the second rule means “OR” in a regular expression.
The key point here is that we can look at the rules and aid in understanding exactly why these rules will code a specific verbatim. This is the explainable part of the model. Moreover, we can change the model “by hand”. It may be that in our set of training examples no respondent said that she loved the ad. Still, we might want to match such verbatims to this code. We can simply change the expressions to:
like|love
to match such verbatims. This is the correctable part of the model.
Applying the Machine Learning Model
When we want to use our machine learning model to code a set of uncoded verbatims, the computer performs these steps:
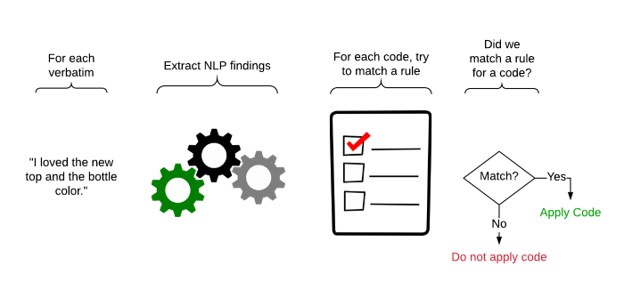
For newly created models you can be sure that it will not code all the verbatims correctly. You will want to check and correct the coding. Having done that, you should explore the model to tune it so that it does not make these mistakes again.
Exploring the Machine Learning Model
The beauty of an explainable machine learning model is that you can understand exactly how the model makes its decisions. Let’s suppose that our model has applied a code incorrectly. This is a False Positive. Assuming we have a reasonable design surface for the model we can look at the verbatim and discover exactly what rule caused it to apply the code incorrectly. Once we know that we can change the rule to help prevent it from making that incorrect decision.
The same is true when the model does not apply a code that it should, a False Negative. In this case we can look at the rules for the code, and at the findings for the verbatim analysis and add a new rule that will match and support the verbatim. Again, a good design surface is needed here. We want to be able to verify that our rule correctly matches the desired verbatim, but we also want to check whether the new rule introduces any False Positives in other verbatims.
Upward Accuracy Spiral
If you are following closely you can see that the model could be constructed without the aid of the computer. A human could create and review all of the rules by hand. We must emphasize that in our approach the model is created by the computer completely automatically.
With a traditional opaque machine learning model, the only tool you have to improve the model is to improve the training set. With the approach we have outlined here that technique remains valid. But in addition, you can understand and correct problems in the model without curating a new training set. How you elect to blend these approaches is up to you, but unless you spend the time to do careful quality checking of the training set manual correction of the model is preferred. This avoids the frumious downward accuracy spiral.
With a new model you should inspect and correct the coding each time the model is used to code a new set of verbatims, then explore the model and tune it to avoid these mistakes. After a few such cycles you may pronounce the model to have acceptable accuracy and forego this correction and tuning cycle.
Mixing in Traditional Machine Learning
The explainable machine learning model we have described has the tremendous advantage of putting us in full control of the model. We can tell exactly why it makes its decisions and correct it when needed. Unfortunately, this comes at a price relative to traditional machine learning.
Traditional machine learning models do not follow a rigid set of rules like those we have described above. They use a probabilistic approach. Given a verbatim to code, a traditional machine learning model can make the pronouncement: “Code 34 should be applied to this verbatim with 93% confidence.” Another way to look at this is that the model says: “based on the training examples I was given my statistical model predicts Code 34 with 93% probability.”
The big advantage to this technique is that this probabilistic approach has a better chance of matching verbatims that are similar to the training examples. In practice, the traditional machine learning approach can increase the number of true positives but will also increase the number of false positives. To incorporate traditional machine learning into our approach we need a way to screen out these false positives.
At Ascribe, we are taking the approach of allowing the user to specify that a traditional model may be used in conjunction with the explainable model. Each of the rules in the explainable model can be optionally marked to use the predictions from the traditional model. Such rules apply codes based on the traditional model but only if the other criteria in the rule are satisfied.
Returning to the code:
- Liked advertisement / product description
We could write a rule that says: “use the traditional machine learning model to predict this code but accept the prediction only if the verbatim contains one of the words “ad”, “advertisement”, or “description”. In this way we gained control over the false positives from the traditional machine learning model. We gain the advantages of the opaque traditional machine learning model but remain in control.
Machine Learning for Verbatim Coding
Using machine learning to decrease manual labor in verbatim coding has been a tantalizing goal for years. The industry has seen several attempts end with marginal labor improvements coupled with decreased accuracy.
Ascribe Coder is today the benchmark for labor savings, providing several semi-automated tools for labor reduction. We believe the techniques described above will provide a breakthrough improvement in coding efficiency at accepted accuracy standards.
A machine learning tool that really delivers on the promise of speed and accuracy has many benefits for the industry. Decreased labor costs is certainly one advantage. Beyond this, project turn-around time can be dramatically reduced. We believe that market researchers will be able to offer the advantages of open-end questions in surveys where cost or speed had precluded them. Empowering the industry to produce quality research faster and cheaper has been our vision at Ascribe for two decades. We look forward to this next advance in using open-end questions for high-quality, cost effective research.